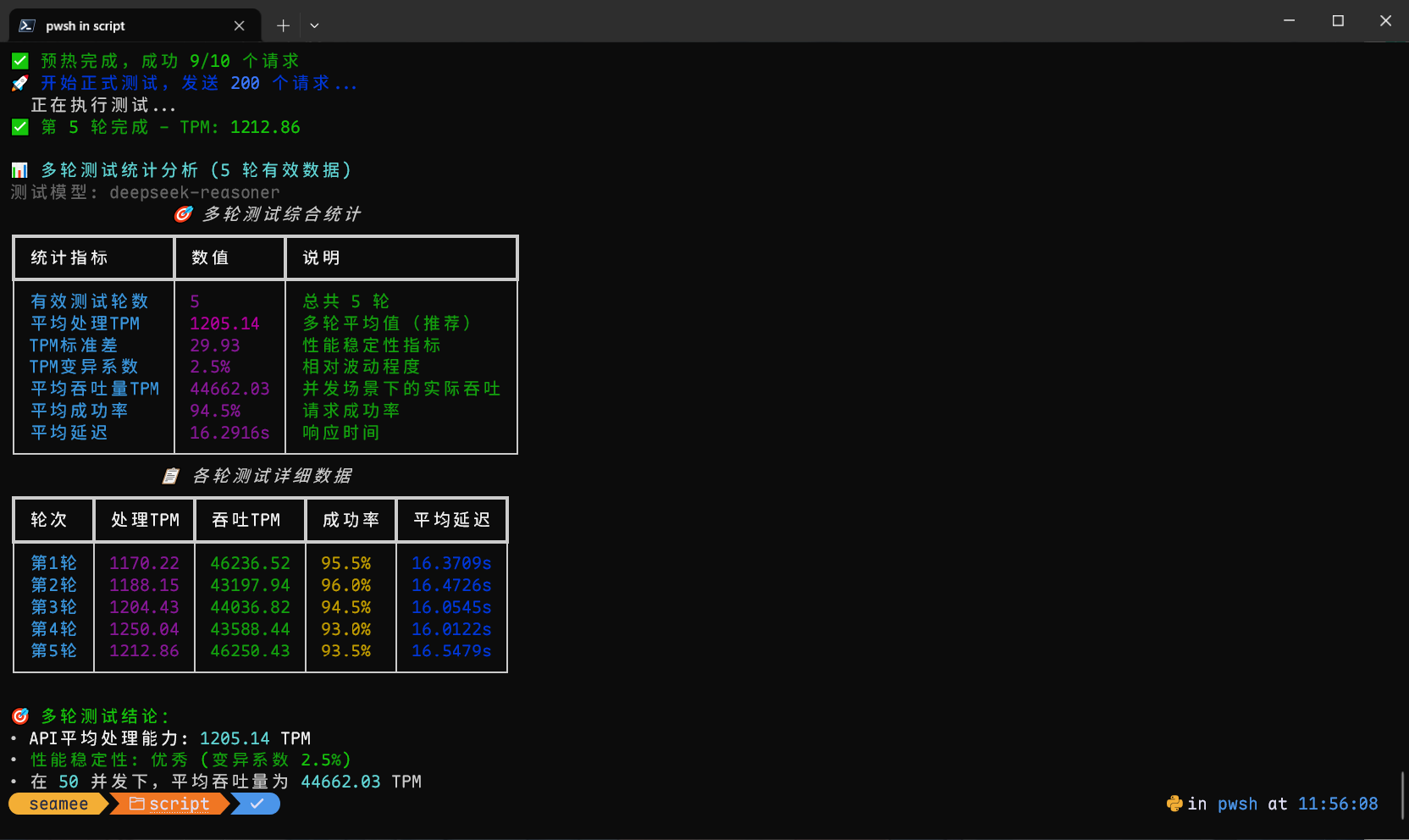
Seamee API is a unified gateway for accessing various large language models (LLMs) and AI services. It offers standardized API endpoints compatible with OpenAI's format, allowing users to switch between different providers by changing the base URL. Key endpoints include chat completions, embeddings, image generation/editing, audio processing (speech, transcription, translation), and model listings. Supported providers include OpenAI, Claude, Gemini, Grok, MoonshotAI, Zhipu, DeepSeek, Qwen, Midjourney, and over 30 others. The service emphasizes competitive pricing and stability without subscription requirements, operating in a self-use mode where users can obtain API keys through the console.